Look, Listen and Learn - A Multimodal LSTM for Speaker Identification
Jimmy SJ. Ren1 Yongtao Hu2 Yu-Wing Tai1 Chuan Wang2 Li Xu1 Wenxiu Sun1 Qiong Yan1
1SenseTime Group Limited, Hong Kong 2The University of Hong Kong, Hong Kong
The 30th AAAI Conference on Artificial Intelligence (AAAI 2016)
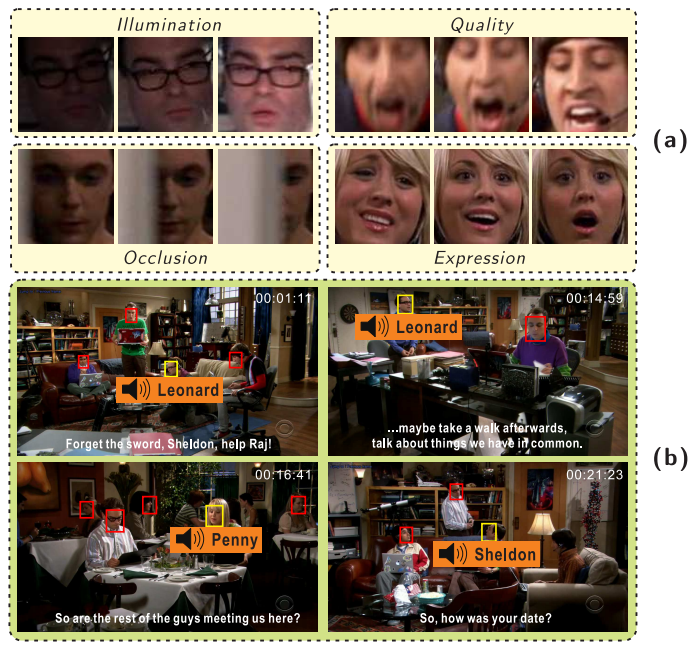
Figure: (a) Face sequence with different kinds of degradations and variations. Using the previous CNN methods cannot recognize the speakers correctly. In contrast, the speakers can be successfully recognized by our LSTM in both single-modal and multimodal settings. (b) Our multimodal LSTM is robust to both image degradation and distractors. Yellow bounding boxes are the speakers. Red bounding boxes are the non-speakers, the distractors.
Abstract
Speaker identification refers to the task of localizing the face of a person who has the same identity as the ongoing voice in a video. This task not only requires collective perception over both visual and auditory signals, the robustness to handle severe quality degradations and unconstrained content variations are also indispensable. In this paper, we describe a novel multimodal Long Short-Term Memory (LSTM) architecture which seamlessly unifies both visual and auditory modalities from the beginning of each sequence input. The key idea is to extend the conventional LSTM by not only sharing weights across time steps, but also sharing weights across modalities. We show that modeling the temporal dependency across face and voice can significantly improve the robustness to content quality degradations and variations. We also found that our multimodal LSTM is robustness to distractors, namely the non-speaking identities. We applied our multimodal LSTM to The Big Bang Theory dataset and showed that our system outperforms the state-of-the-art systems in speaker identification with lower false alarm rate and higher recognition accuracy.
Downloads
|
|||||
|
|||||
|
Bibtex
@inproceedings{ren2016look,
title={Look, Listen and Learn - A Multimodal LSTM for Speaker Identification},
author={Ren, Jimmy SJ. and Hu, Yongtao and Tai, Yu-Wing and Wang, Chuan and Xu, Li and Sun, Wenxiu and Yan, Qiong},
booktitle={Proceedings of the 30th AAAI Conference on Artificial Intelligence},
pages={3581--3587},
year={2016}
}